Questions¶
Probabilistic Models¶
Problem 1
Consider the definition of conditional probability: $$ P(A,B) = P(A|B)P(B) $$ Can you come up with a simple explanation in words as to why this works? Use similar reasoning to come up with an expression for \(P(A,B|C)\).
Problem 2
1% of women at age forty who participate in routine screening have breast cancer. 80% of women with breast cancer will get positive mammographies. 9.6% of women without breast cancer will also get positive mammographies. A woman in this age group had a positive mammography in a routine screening. What is the probability that she actually has breast cancer?
Problem 3
There is a 50% chance there is both life and water on Mars, a 25% chance there is life but no water, and a 25% chance there is no life and no water. What is the probability that there is life on Mars given that there is water?
Problem 4
In the textbook, it is stated that if all variables in a Bayesian network are binary, the probability distribution over some variable \(X\) with \(n\) parents \(\textrm{Pa}_X\) can be represented by \(2^n\) independent parameters.
Imagine that \(X\) is a binary variable with two parent variables that are not necessarily binary. Imagine that the first parent can assume three different values, and that the second can assume two values. How many independent parameters are needed to represent this distribution ( \( P(X |\textrm{Pa}_X) \) )? How many would it be if you added another parent that can assume four different values?
Now assume that \(X\) itself is not binary, but can assume three different values (and still has the three parents as specified above). How many values are needed to represent this distribution? Can you come up with a general rule for the number of independent parameters needed to represent a distribution over some variable \( X \) with parents \( \textrm{Pa}_X \)?
Problem 5
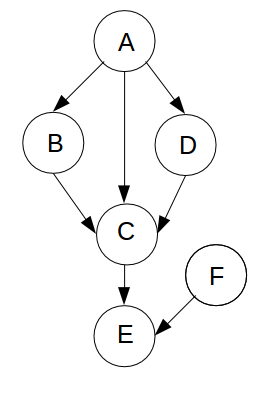
Given the displayed Bayes net, determine whether the following are true or false:
- \( (B\perp D | A) \)
- \( (B\perp D | C) \)
- \( (B\perp D | E) \)
- \( (B\perp C | A) \)
Problem 6
It is known that 80-foot blue whales consume, on average, 3200 kg of krill per day. 100-footers consume on average 3600 kg of krill per day. Assume that the mean daily krill consumption varies linearly with whale length and that the daily consumption for a given whale follows a Gaussian distribution with a standard deviation of 200 kg of krill per day. Define the linear Gaussian distribution, \( P(k \mid l) \), relating the rate of krill consumption \(k\) to whale length \(l\).
Problem 7
Assuming a hidden Markov model with states \( s_{0:t} \) and observations \( o_{0:t} \), prove the following:
$$ P(s_t \mid o_{0:t}) \propto P(o_t \mid s_t, o_{0:t-1}) P(s_t \mid o_{0:t-1}) $$Starting from the previous equation, prove the following: $$ P\left(s_t \mid o_{0:t}\right) \propto P\left(o_t \mid s_t \right) \sum_{s_{t-1}} P\left(s_t \mid s_{t-1}\right) P\left( s_{t-1} \mid o_{0:t-1} \right)$$
Problem 8
What is the Markov blanket for some node \( o_t \) of the hidden Markov model below? Explain why this is so.
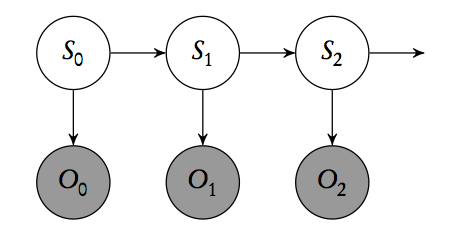
Problem 9
One possible representation of the law of total probability is:
$$ P(A) = \sum_{B \in B_{set}} P(A \mid B) P(B) $$
where \( B_{set} \) is a set of mutually exclusive and exhaustive propositions. Can you find a similar expression for \( P(A \mid C) \)?
Problem 10 What is a topological sort? Why is it important to perform a topological sort before sampling from a Bayesian network? Does a topological sort always exist? Is a topological sort always unique?
Problem 11 Formulate the following 3SAT problem as a Bayesian network. $$F(x_1, x_2, x_3, x_4) = (x_1 \vee x_2 \vee x_3) \wedge (\neg x_1 \vee x_2 \vee \neg x_4) \wedge (x_2 \vee x_3 \vee x_4) $$
This shows that inference in Bayesian networks is at least as hard as 3SAT. If 3SAT is NP-complete, what does that make inference in Bayesian networks?
Problem 12 What are the differences between inference, parameter learning, and structure learning? What are you looking for in each case and what is assumed to be known? When might you use each of them?
Problem 13 What is a classification task? Assume you are classifying using a naive Bayes model. What assumptions are you making? Draw a naive Bayes model using the compact representation shown in class. What is the name of this kind of representation?
Problem 14.1 What is an important drawback of maximum likelihood estimation?
Problem 14.2 Bayesian parameter learning estimates a posterior \(p(\theta \mid D)\) for the parameters \(\theta\) given the data \(D\). What are some of its advantages and drawbacks?
Problem 15 What is the gamma function \( \Gamma \) ? What is \( \Gamma(5) \) ?
Problem 16 Imagine that you want to estimate \(\theta\), the probability that one basketball team (call them Team A) beats another team (call them Team B). Assume you know nothing else about the two teams. What is a reasonable prior distribution?
Now imagine that you know the two teams well and are confident that they are evenly matched. Would a prior of Beta(9,9) be better than a Beta(2,2) in this case? If so, why?
Now imagine that you know that Team A is more likely to win (maybe they are the Warriors). What kind of prior might you use in this case? Imagine that the teams are going to play many games against each other. What does this mean for the prior you select?
Problem 17 Consider the two Beta distributions Beta(2,2) and Beta(9,9). Beta(9,9) gives much more weight to \(\theta=0.5\). Can you explain intuitively why this is so?
Problem 18 Suppose you have a lot of data and are trying to learn the structure of a Bayesian network that fits this data. Consider two arbitrary Bayesian network designs. One is relatively sparse, whereas the other has many connections between its nodes.
Imagine that your data consists of very few samples. Which Bayesian network would you expect to achieve a better Bayesian score? How would this change if there were many samples?
Problem 19 How many members are there in the Markov equivalence class represented by the partially directed graph shown below?
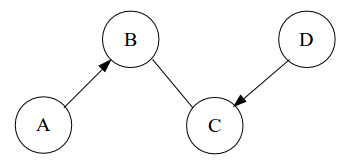
Problem 20 Gibbs sampling offers a fast way to produce samples with which to estimate a distribution. What are some downsides of Gibbs sampling and how are they handled?
Problem 21 What is a topological sorting of the nodes shown in Question 5 (recreated below)?