Questions¶
Decision Problems¶
Problem 1 What does it mean to be rational?
Problem 2 Explain the value of information in words. What is the value of information of an observation that does not change the optimal action? Imagine that the optimal action changes after an observation. What does this say about the value of information of that observation?
Problem 3 The prisoners dilemma is an example of a game with a dominant strategy equilibrium. Imagine that the game is modified so that if one prisoner testifies the other only gets four years of prison instead of ten. Does this game still have a dominant strategy equilibrium? Are there any other equilibria?
Problem 4 Explain why the traveler's dilemma has a unique Nash equilibrium of $2. Draw the utility matrix and use it to show the equilibrium.
Problem 5 What is the Nash equilibrium for a game with the following payoff matrix?
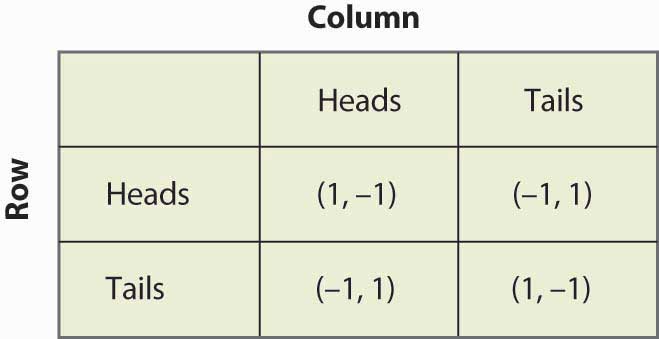
Sequential Problems¶
Problem 1 What is the Markov assumption? What does a Markov decision process consist of? What is a stationary MDP? Draw a compact representation of a stationary MDP.
Problem 2 What is the purpose of the discount factor in infinite horizon problems? What is an alternative to using a discount factor in infinite horizon problems? What effect does a small discount factor have? What about a large one? When is one preferable to the other?
Problem 3 Does the optimal policy have to be unique? Does the optimal value for each state have to be unique?
Problem 4 What is the Bellman equation? How does it simplify if transitions are deterministic?
Problem 5 The policy evaluation equation in matrix form is
$$ \bf{U}^{\pi} = (\bf{I} - \gamma \bf{T}^{\pi})^{-1} \bf{R}^{\pi} $$where \( \bf{U}^{\pi} \) and \( \bf{R}^{\pi} \) are the utility and reward functions represented as vectors. What is the meaning of \(\bf{T}^{\pi}\)?. How does this to relate Markov decision processes and Markov chains?
Problem 6 What is dynamic programming? Can you give an example? Why is dynamic programming more efficient than brute force methods for solving MDPs?
Problem 7 Can you explain what policy iteration and value iteration are? What are their similarities and differences?
Problem 8 What is the difference between open and closed-loop planning?
Problem 9 Consider the simple gridworld shown below. An agent in this world can move to the cell to its immediate left or to the cell to its immediate right, and the transitions are deterministic. Moving left in \(s_1\) gives a reward of 100 and terminates the game. Moving right in \(s_4\) does nothing. Perform value iteration and determine the utility of being in each state assuming a discount factor of 0.9.
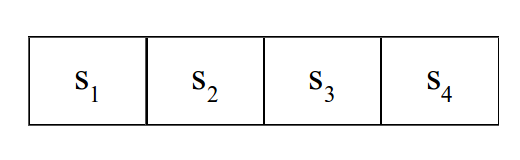
Problem 10 How does asynchronous value iteration differ from standard value iteration? What is the importance of the state ordering?
Apply Gauss-Seidel value iteration to the simple gridworld from the previous problem. First, use a state ordering of \(s_1\), \(s_2\), \(s_3\), \(s_4\). Then use an ordering of \(s_4\), \(s_3\), \(s_2\), \(s_1\). How many iterations did each ordering take to converge?
Problem 11 In what cases would you prefer to use dynamic programming? Approximate dynamic programming? Online methods?
Problem 12 Establish a lower bound on the optimal value function for an MDP with discount factor \( \gamma \). Assume you know the reward \( R(s,a) \) for all states and actions, but do not know the transition function.
Problem 13 a. What is the difference between \( U^{\pi} \) and \( U^{*} \)? b. What is the difference between \( U^{\pi} \) and \( Q^{\pi} \)? Express \( U^{\pi} \) as a function of \( Q^{\pi} \), and vice versa.
Problem 14 Why would you use an online solution technique as opposed to an offline method? Why not?
Model Uncertainty¶
Problem 1 For what types of problems do we use reinforcement learning? What are the two main approaches?
Problem 2 Why is the concept of exploration versus exploitation so important in reinforcement learning?
What is a multi-armed bandit? Describe the various parameters involved in a multi-armed bandit problem. Imagine you have a two-armed bandit and are convinced that one of the levers yields a payout of $1 with probability 0.9. You have never pulled the other lever, and are unsure if it has any payout. Relate this to the problem of exploration and exploitation.
Problem 3 Supose we have a two-armed bandit. Our estimate of the payout rate of the first lever is 0.7, and our estimate of the payout rate for the second lever is 0.6. That is, \(\rho_1 = 0.7\) and \(\rho_2 = 0.6\). Our 95% confidence intervals for \(\theta_1\) and \(\theta_2\) are (0.6, 0.8) and (0.3, 0.9), respectively.
What is the difference between \(\theta_i\) and \(\rho_i\)? Suppose you used an \(\epsilon\)-greedy strategy with \(\epsilon = 0.5\). How might you decide what lever to pull? Suppose you used an interval exploration strategy with 95% confidence intervals. What lever would you pull?
Problem 4 What are Q-values and how do they differ from utility values U? Imagine you have a model of the reward and transition functions. If you were to run a value iteration using the Q-values instead of the utility values U, what would be the update equation?
Problem 5 What is the central equation behind incremental estimation? Identify the temporal difference error and the learning rate. Imagine you have an estimate of some random variable \(X\). Imagine that this estimate is \(\hat{x} = 3\). If the learning rate is 0.1, what happens to your estimate after observing a new sample \(x = 7\)? What happens if the learning rate is 0.5? Comment on the effect that learning rate has on incremental estimation.
Problem 6 What are the similarities and differences between Q-learning and Sarsa?
Problem 7 Use Q-values, the Bellman equation, and the incremental update equation to derive the update equations for Q-learning and Sarsa.
Problem 8 What is the difference between Sarsa and Sarsa(\(\lambda\))? What types of problems can be solved more efficiently using eligibility traces?
Problem 9 What are the differences between model-based reinforcement learning and model-free reinforcement learning in terms of the quality of the learned policy and computational cost?
Problem 10 Use the temporal difference equation to derive a value function update for samples of the form \( (s,s',r) \). Is the resulting algorithm model-based or model-free?
Problem 11 When is Generalization needed in the context of model uncertainty? Describe different Generalization methods.
State Uncertainty¶
Problem 1 What is a POMDP and how does it differ from an MDP? Draw the structure of a POMDP and compare it to that of an MDP.
Problem 2 Examine the two gridworlds shown below. In the left-most gridworld, you know the position of the agent, represented by the red square. In the right-most gridworld, you only have a probability distribution over possible states. How might you represent the "state" for each case? Use this to explain why POMDPs are sometimes called "belief-state MDPs" and are generally intractable.
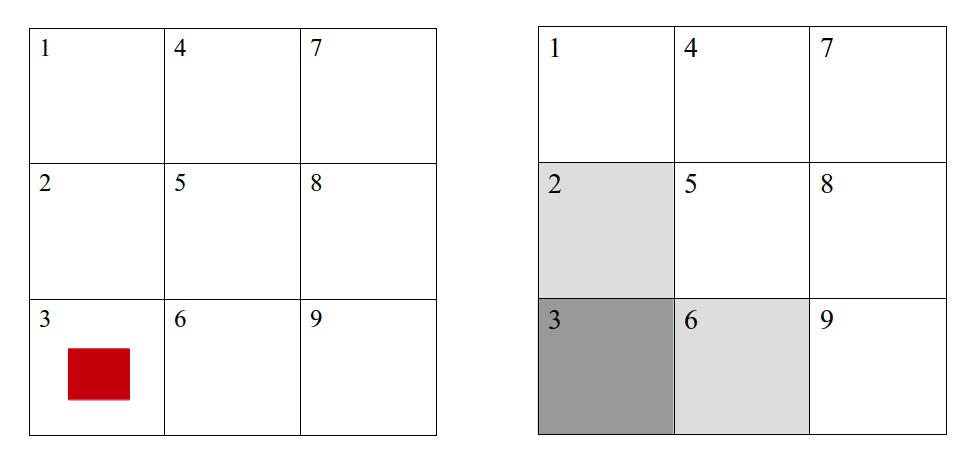
Problem 3 A key to solving POMDPs is the ability to maintain a belief, or probability distribution, over states. What methods can be used to update beliefs? When might one be preferred over the others?
Problem 4 Derive the following equation for a discrete state filter:
$$ b'(s') \propto O(o \mid s', a)\sum_{s}T(s'\mid s, a)b(s) $$from the definition of a belief update \( b'(s') = P(s' \mid o, a, b) \).
Problem 5 Why would you use a particle filter with rejection? Why would you use a particle filter without rejection? Why is it better to use a larger number of particles in your particle filter? What is particle deprivation, and how can you prevent it?
Problem 6 Work through the crying baby example presented in the textbook. Work through the math, updating your belief with the actions and observations given. Verify that your numbers match those in the text.
Problem 7 In MDPs, the policy is a mapping from states to actions. What does a POMDP policy look like? How do you use this policy to find the utility of a belief state?
Problem 8 Imagine you have an exam tomorrow, but there is a non-negligible chance the professor and TAs forgot about the exam. You have a choice: you can study, or you can take the evening off. If you study and there is an exam, you get a reward of 100. If you study and there is no exam, you receive no reward. If you take the evening off and there is no exam, the enjoyment of not studying gives you a reward of 100. But if you take the evening off and there is an exam, the certain F and associated stress give you a reward of -100.
Write down the alpha vectors for this problem. How sure should you be that there will be no exam before you take the evening off? Imagine you have a third option, which is to drop out of school and live in the wilderness. This simple lifestyle would give you a reward of 30, regardless of whether the exam takes place or not. What can you say about this option? Would you ever take it?
Problem 9 Imagine that you have already solved for the policy of a 3-state POMDP, and you have the following alpha vectors:
$$ \begin{pmatrix} 300 \\\ 100 \\\ 0\end{pmatrix}, \begin{pmatrix} 167 \\\ 10 \\\ 100\end{pmatrix}, \begin{pmatrix} 27 \\\ 50 \\\ 50\end{pmatrix} $$The first and third alpha vectors correspond to action 1, and the second alpha vector corresponds to action 2.
Is this even a valid policy? Can you have multiple alpha vectors per action? If the policy is valid, determine the action you would take given you have the following belief: 0% chance in state 1, 70% chance in state 2, 30% chance in state 3.
Problem 10 What does it mean to solve a POMDP offline versus solving it online? What are the advantages and disadvantages of each? How do QMDP, FIB, and point-based value iteration work? What are the advantages and disadvantages of each?
Problem 11 The update equation for QMDP is shown below.
$$ \alpha_a^{(k+1)}(s) = R(s,a) + \gamma \sum_{s'}T(s' \mid s,a) \max_{a'} \alpha_{a'}^{(k)}(s') $$How many operations does each iteration take? Compare this with the number of operations required per iteration required for FIB, whose update equation is shown below.
$$ \alpha_a^{(k+1)}(s) = R(s,a) + \gamma \sum_o \max_{a'} \sum_{s'}O(o\mid s',a)T(s' \mid s,a) \alpha_{a'}^{(k)}(s') $$Write code that applies both QMDP and FIB to the crying baby problem.